
cron, dbt Cloud, and Airflow: 3 ways to deploy dbt


This is an old post I wrote for dbt’s blog that didn’t end up getting published. I’m putting it here since I’ve been referencing it again with one of my clients and figured other folks might find it useful. Thanks to David Krevitt at dbt for his edits.
Overview
In this post, I’m going to walk through a very contained deployment example: given an existing dbt repo and data warehouse, run your dbt project on a schedule i.e. “deploy” your project.
This assumes you have the following already set up:
An existing dbt project repo (see my example based on the dbt tutorial)
A data warehouse set up (I’d recommend creating a Bigquery project to follow along)
There are many possible deployment environments between “local” and “production”. For example, you could set up a separate “staging” environment that runs your project in a staging schema when someone opens a pull request. To help focus this walkthrough, I will not cover staging environments.
Broadly speaking, there are three ways deploy dbt:
cron
dbt Cloud
A general workflow scheduler like Airflow
I will walk through example deployments of each of these solutions in the next sections, but here is a quick comparison of these three options.
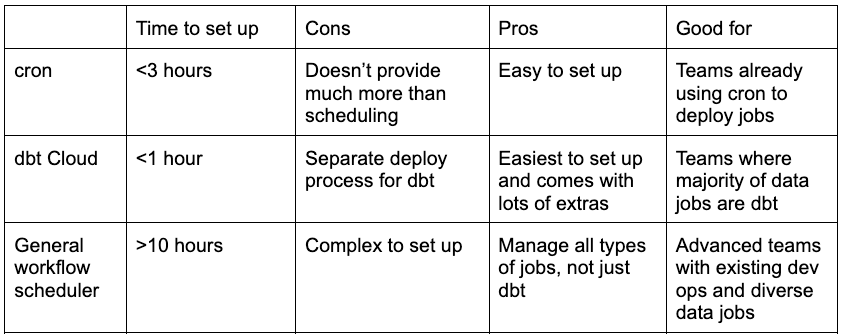
Cron
Cron is the battle-tested time-interval scheduler that comes by default on Unix-based machines. To deploy dbt with cron, you repeat the same process you did to set up dbt locally, but this time on a cloud instance.
Pros:
Easy to set up (and for existing orgs, probably already exists in some form)
Essentially free
Extremely portable (pretty much every machine runs cron)
Cons:
Alerting and logging requires set up
May be more challenging for those with little cloud or engineering experience
Good for: Teams already using cron to deploy jobs, but little else.
Example setup
Time to set up: <3 hours

In this example, I used AWS EC2, but the same broad concepts apply to any cloud provider. This walkthrough references my scratch dbt repo, so I’d recommend forking that before getting started.
Set up an EC2 prod instance via this tutorial
SSH into your new instance and install git:
yum install gitCreate a Github deploy key for your dbt repo
git clone the repository onto the EC2
cdinto that repo and install dbt on the EC2 via virtual envpython -m venv dbt-envpython -m pip install -r requirements.txt
Get BigQuery credentials
Create a new Bigquery prod service account
Download keys locally
Upload to EC2 (via scp)
Configure profiles.yml on the EC2
Confirm the EC2 can connect to BigQuery with a
dbt debugand adbt runMake the run script executable
Schedule the run script every 10 minutes
crontab -eAdd following line:
*/10 * * * * /home/ec2-user/dbt-tutorial/run.sh
Alerts
Nothing is built in by default, but you can set up something simple like healthchecks.io to send you an email.
Logs
ssh into your EC2 running dbt, then tail -f /var/spool/mail/ec2-user.
Final remarks
I wouldn’t recommend this approach, even to start. Why? Because there are now solutions that are both easier to set up and more robust.
dbt Cloud
Enter dbt Cloud. This is the fastest approach, especially for those not super experienced in the broader cloud ecosystem.
Pros:
Easiest to set up
Comes with a bunch of extras, like dbt docs hosting and github CI integration
Cons:
Might be confusing to have a separate deploy system just for dbt
Good for: Teams where dbt (or SQL) is the vast majority of their data pipelining stack.
Example setup
Time to set up: <1 hour
Sign up for an account (free for one developer).
It’s pretty much point and click from there and dbt Cloud has good quickstart docs

Alerts
Set up Slack integrations and/or email on run failures natively in the web app. Pro tip: I also set up the github slack integration in the same channel so you could quickly see in one place the most recent commit that created the error.
Logs
These are also viewable natively in the web app. You also get a free deployment of the dbt docs site i.e. a free “data catalog”.
Final remarks
dbt Cloud is great, especially if >90% of your workflows are in dbt. Over time though, it might be a bit strange to have a separate system deploy your dbt jobs. Most organizations have many types of scripts running other than dbt e.g. custom python loading scripts or data science pipelines.
This brings us to our final flavor; a deployment that handles all jobs and provides the greatest flexibility.
General workflow scheduler: Airflow
Time to set up: >10 hours
The basic idea of a general workflow scheduler is to solely handle the task of deciding when and what should run, regardless of the underlying job that is running. Whereas dbt Cloud by definition only orchestrates dbt jobs, general workflow schedulers can orchestrate any kind of job e.g. a python script that scrapes data from a website and writes it to a database.
Pros:
Schedule more than just dbt jobs and chain your dbt jobs to other jobs
Use a stack that is likely closer to the engineering org as a whole, maximizing the impact of a single dev ops team and enabling knowledge sharing
Cons:
Requires proficient knowledge of cloud technologies
More complex system with many parts that will require on-going maintenance
Good for: Advanced teams with existing dev ops and a more diverse data stack than just dbt.
Example setup
In this walkthrough, I’m going to use Airflow as an example of a general workflow scheduler. Specifically, I’m going to deploy dbt on Google’s managed Airflow called Cloud Composer.
Special shoutout to the dbt slack channel. I searched “dbt composer” and was pointed to this helpful thread.
The general flow looks like this:
Build your dbt project as a Docker image and push the image to Container Registry
Upload a Kubernetes Pod Operator-based dag.py to Cloud Composer
Trigger the rest in Cloud Composer’s Airflow UI
A very brief intro to containers is in order. Disclaimer: I am not a containerization expert. For those who relate, allow me to briefly share the mental model I use to think about how all these systems relate to each other. I also found the Docker Orientation and Setup walkthrough and Illustrated Children’s Guide to Kubernetes very helpful.
Interlude: A restaurant manager
Imagine you run a three-star Michelin restaurant. You only serve a fixed three-course meal to all your guests. What do you need to be successful?
A recipe: A list of instructions detailing how to make each dish
A dish: A single instantiation of that recipe
A team of chefs: A group of people who do the work of creating the dish based on the recipe
A head chef: Someone responsible for the overall menu i.e. order of the recipes
Here is how the technologies map in this simple analogy:
Docker image: a recipe
Docker container: a dish based on that recipe
Kubernetes: chefs (responsible for cooking the dishes)
Airflow: head chef (responsible for the overall menu i.e. order of the dishes)
To bring it all home, your dbt project gets packaged into a Docker image which includes all the dependencies (e.g. dbt-bigquery==1.3.0) and source code (e.g. our dbt models and tests) needed to run the project. This image gets pushed to a repository (e.g. Google Container Registry). You then use the Airflow framework to write dags that specify how the containers should be run and in what order. Kubernetes does the work of creating, running, and managing the lifecylce of those containers.
GCP’s Cloud Composer packages a ready-made Airflow deployment running on top of a managed Kubernetes cluster (a.k.a. GKE). It hosts the Airflow UI for you and reads dags from a special GCS bucket. Considering how many systems are involved in a traditional Airflow deployment, it’s super helpful to have a single place to manage everything.

What my Composer environment looks like (note the DAGs folder and Airflow web UI links at the bottom)
Side note: If you’re not a Google Cloud customer, Astronomer offers a similar “managed Airflow” product.
Publishing your dbt project as a Docker image
To create a Docker image, you need to write a Dockerfile. I based my Dockerfile on the official one in fishtown’s repo with some slight modifications. At a high level, here is what the “recipe” for creating a dbt ephemeral container job looks like:
Start with a standard python Docker image (3.8 in this case)
Install some basic system dependencies (e.g. git)
Install the python requirements (in this case just dbt)
Copy the jaffle-shop / dbt code into the container
To build the image locally, cd into the same directory as the Dockerfile and run:
docker build -t dbt
Now run this newly created image as a container and open up a shell into it:
docker run -it dbt bash
You now are in a running container based on the image we just created. You can type normal Unix commands to look around (e.g. hit ls and see that our jaffle-shop code is correctly copied in).
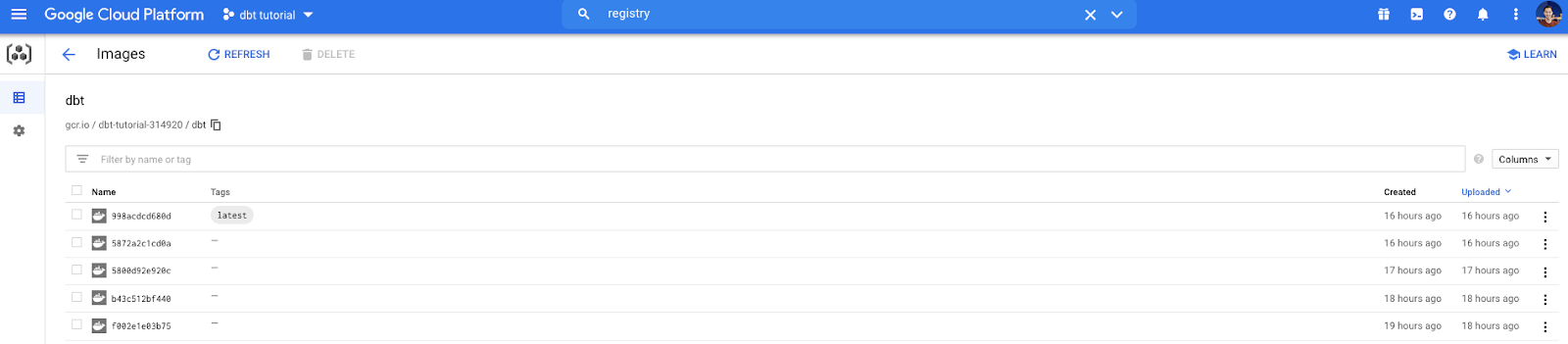
Now push this newly created image to Google’s Container Registry (GCR):
gcloud auth login
gcloud auth configure-docker
docker tag dbt gcr.io/dbt-tutorial-314920/dbt --this essentially just renames the image
docker push gcr.io/dbt-tutorial-314920/dbt
I can now see this image (and all other past pushes) in GCR:
This is still a manual process in that I have to manually build and push the image. Eventually, you’ll want to use something like Github Actions to build and push the image every time you merge to master in your github repo.
Write your first Airflow dag
At a high level, our example dag:
Mounts our google service account key as a volume so containers can connect to BigQuery
Spins up a Kubernetes Pod to execute
dbt runin a container (based on the image we published in the previous step)Spins up a Kubernetes Pod to execute
dbt testin a container after the previous step has finished
Before moving forward, read and/or re-read this excellent piece about the KubernetesPodOperator and Airflow. The tldr is perfect: “only use KubernetesPodOperators” when it comes to Airflow. If you try to install dbt directly into your Composer environment, you’re almost guaranteed to run into python dependency issues.
The example dag I use is here. I won’t go into the details of each line, but will just make a few callouts:
You first need to add your bigquery service account key as a Kubernetes secret, which this walkthrough describes well (you can ignore the env variable example and just do the service account example). Make sure the deploy_target + key in your airflow dag matches the keyfile argument in your profiles.yml.
Make sure image_pull_policy = ‘Always’. Its default behavior is to cache the image, which created a lot of headache for me trying to understand why recent image changes weren’t getting picked up by Airflow.
To “deploy” this dag, upload the file to the associated GCS bucket in your composer project:

Like with the Docker image build process, you’ll eventually want to implement a continuous delivery cycle to upload to this GCS bucket automatically when your code gets merged.
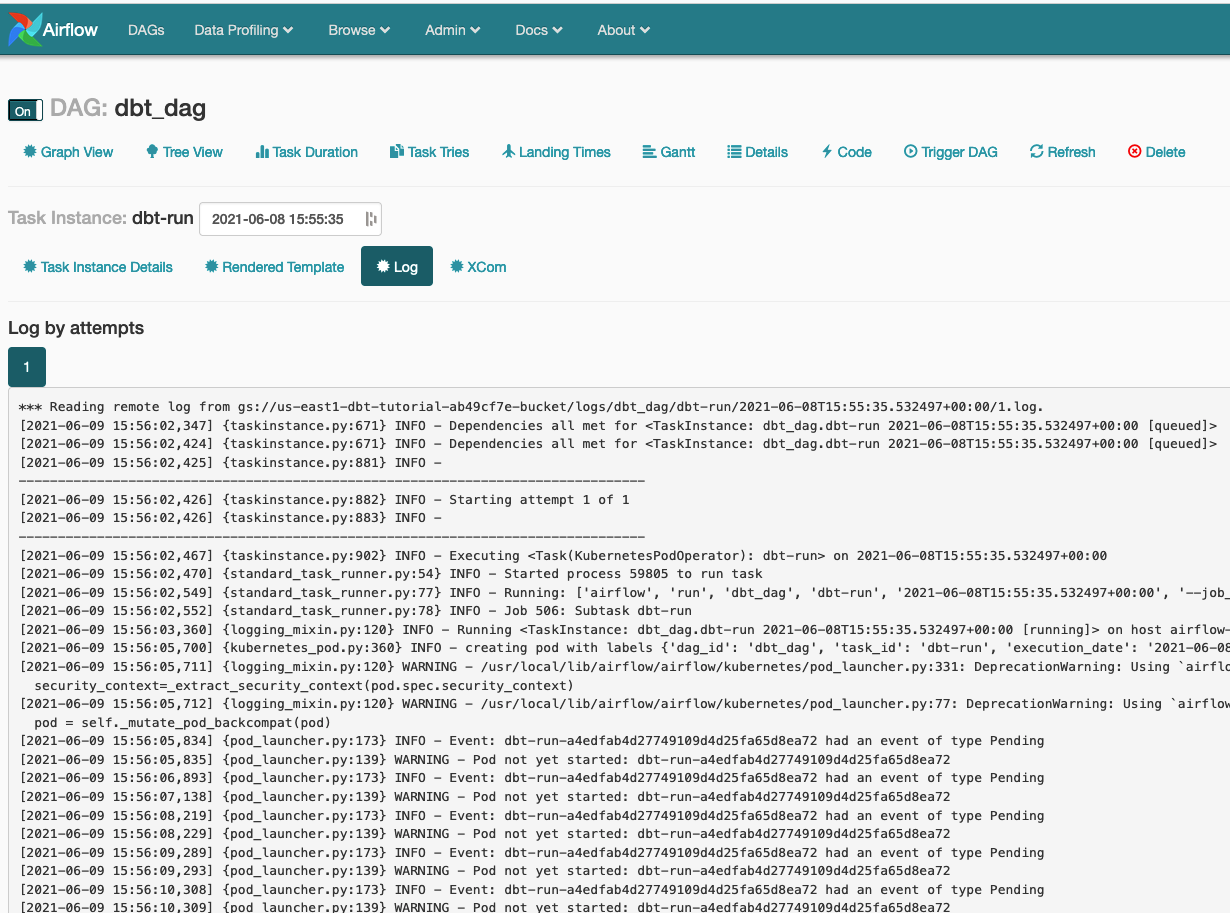
Trigger Airflow jobs
Go to the Airflow UI within Cloud Composers. Here you can trigger manual runs, see logs, and task instance details.

The test failure is intended, I swear :)
Alerts
Cloud Composer ships with alerting policies:

Logs
Viewable in the Airflow UI:
Final Remarks
That was a lot more involved than I had initially expected for a “fully managed” solution 😅. Even this basic implementation took me at least 10x the time it took to set up dbt Cloud and 3x the time to set up cron. Granted, I had limited Docker, Kubernetes, and GCP experience coming in, so my learning curve was particularly steep.
I think a good compromise between the ease of use of dbt Cloud and the flexibility of a general workflow scheduler could be using the dbt Cloud API (there’s a very helpful dbt Cloud + Airflow walkthrough on dbt’s website). Sign up for dbt Cloud in the beginning for speed and then make calls to the API in an Airflow dag only when you need to chain dbt with other parts of your data stack.
Closing thoughts
Here my decision framework for picking tools. In order of importance:
Time saved
Cons
Pros
The most important job of a tool is to save time for your team. Time is the most precious (and expensive) asset of your company (and, well, life in general). And given engineering salaries, even saving one hour of an engineer’s time every week will likely pay for the cost of the tool itself. Viewed from this lens, dbt Cloud is the clear best option to run dbt in production.
The next step is to make sure the cons of the tool are not dealbreakers. Is it okay for your organization to run dbt in a separate process from the rest of the data jobs? Do you have a lot of other non-dbt data jobs?
Finally, you can evaluate whether or not you’ll be able to leverage the unique advantages the tool offers you. Will having the dbt docs site automatically deployed through dbt Cloud save you time in the future from having to deploy your own docs site? Do you have more junior analysts on the team that would get a lot of value out of the dbt Cloud IDE?
cron, dbt Cloud, Airflow; there’s a place for each of these solutions, and regardless which solution you take, I hope this walkthrough makes it easier for you to get your dbt deployment process to the next level.